
At Z1, diving into a software project involves engaging with a crucial but elusive element—architecture. As Martin Fowler and Ralph Johnson stated: "Architecture is about the important stuff. Whatever that is."
The nature of software development, unlike traditional construction projects, defies complete upfront specifications. Software architecture unfolds during the whole development phase. Design choices often reveal themselves after the code is working. This landscape of discovery, where challenges and solutions emerge organically, is particularly pronounced in the case of MVPs and startup projects, which are our specialty. Flexibility, attentive listening, and responsive actions become essential in this context.
Flexibility, attentive listening, and responsive actions become essential in MVPs and startup projects, which are Z1's specialty.
We have an engineering team of +30 devs specialized in frontend, backend, mobile, and UI, working collaboratively in squads. For them, architecture is, as Fowler also pointed out, "the shared understanding that the team holds of the system design."
In our approach to architecture, our teams have agreed on several balanced trade-offs. Are you curious about how we make software architecture work for real-world projects? While each product presents unique challenges, here we offer a thoughtful collection of perspectives, opinions, and code-related decisions. These decisions enable us to create solid foundations for our development solutions, keeping them easy to maintain and evolve.

Tech and framework choices
At the frontend, React remains our go-to choice for crafting user interfaces. In a rapidly evolving ecosystem, it has become an industry standard, stable, mature, and wildly embraced. Our team deeply understands React and really likes its component-based approach, declarative syntax, and how it still feels close to writing plain JavaScript.
For our clients, it's reassuring to know that with React, they are betting on a framework with a solid history, a promising future, and strong community support. However, we are flexible and ready to embark on adventures with the framework or meta-framework of your liking: Angular, Vue, Astro, Remix, Solid, you name it!
Project specifics guide our decisions. We may create a single-page application (SPA) using React + Vite or harness the power of server rendering with Next.js based on the unique requirements of each project.
At the backend, the team is very well-versed in the use Django, a Python framework with a lot of built-in functionalities that allow our backend team to move quickly. It comes packaged with things like an ORM (Object-Relational Mapping) tool and an admin interface tool. The admin interface is essential. The team will configure it to the detail so our clients have a very granular control panel for managing the frontend app, controlling users and permissions, reading, adding and editing information, etc. The admin panel is configured to cover the specific needs of the client product.
The ORM abstracts away the details of database interaction. Instead of dealing with raw SQL queries, the team can have Python classes that translate into database schemas and tables, speeding development times. The database we use in most cases is PostgresQL. In some cases when a non-relational database is required, we use MongoDB.
Django includes a robust authentication system that handles user authentication, permissions, and session management. It also incorporates security best practices by default and encourages the team to follow secure coding practices.
Strong typing and flexibility across the stack
It has been a while since we started using TypeScript in the frontend, and there's no turning back for us now. It has become essential in our toolkit and is well embedded in our architectural choices. We pair it with a GraphQL API service in the backend to leverage the power of strong typing end-to-end.
Strong types boost our confidence and speed up development. They enhance code predictability and robustness, reduce runtime errors, and ensure consistency. The developer experience is great: the team loves its autocompletion and inline documentation features.
In the backend, we use Django's ORM to model the data and simplify database interactions. This data is made available to the frontend through the GraphQL API. In order to create the GraphQL API, we use a library called Strawberry, which integrates with Django in the backend.
The main advantage for us in using a GraphQL API is that it enables us to have an "evolving" API.
MVPs and first versions come with lots of challenges and discoveries that happen along the way. GraphQL API allows us to introduce new changes on the go, without breaking existing clients.
Since the beginning of the project, backend and frontend teams explore the product domain and agree on an interface contract in the form of a GraphQL schema. One great advantage of GraphQL is its built-in introspection, which is the ability of the API to query its own schema. That empowers our frontend team, which is able to explore the types, fields, and relationships defined in it through a GraphQL playground. This provides the team with excellent common visibility, fosters collaboration, and helps in identifying problems.
Frontend teams can shape and tailor the data to meet UI requirements and have lots of flexibility. For example, they don't need to wait for the backend team to prepare yet another endpoint with a fixed response. Or they can ask for different fields from multiple queries in a single request, which ends up being more efficient and performant.
On top of all this, the frontend team uses a codegen tool to automate the generation of types in the frontend from the GraphQL schema. This way, we remove manual effort, reduce errors, and keep types in sync.
In the end, what we achieve is a fully typed approach across the stack, but we keep a lot of flexibility, which is of great help in a dynamic development environment like ours.
Backend code structure. Containerization and modularity.
The backend app's local environment is a Docker container. For a Python application, this is especially useful as it avoids issues related to different operating systems and versions of Python. It provides the team with a standardized environment with all the required services: Django, PostgreSQL, Redix, Nginx, and Celery. Additionally, we include an SMTP server to validate email communications, a service to query the database directly, and a service to monitor the correct functioning of the async tasks. Along with other specific services the project may require.
In Django, we achieve code modularity through the use of "apps". Django projects are made of multiple apps, each one containing encapsulated functionality related to some entity or concept of the domain. For example, in the case of a language learning platform, we would have apps such as "users", "classes", "students", "teachers", "lessons" and so on. These apps behave like modules or components. They help organize and structure code in a way that promotes modularity, reusability, and maintainability.
Celery helps manage heavy tasks that need to happen in the background while the program does other things. This makes the app run faster and smoother.
A tool the team uses frequently is Celery. It helps manage heavy tasks that need to happen in the background while the program does other things. This makes the app run faster and smoother. Celery can also help with tasks that must be repeated regularly, like checking for updates, backing up data, or connecting asynchronously with external services.
Frontend code structure. Containers, separation of concerns, and co-location.
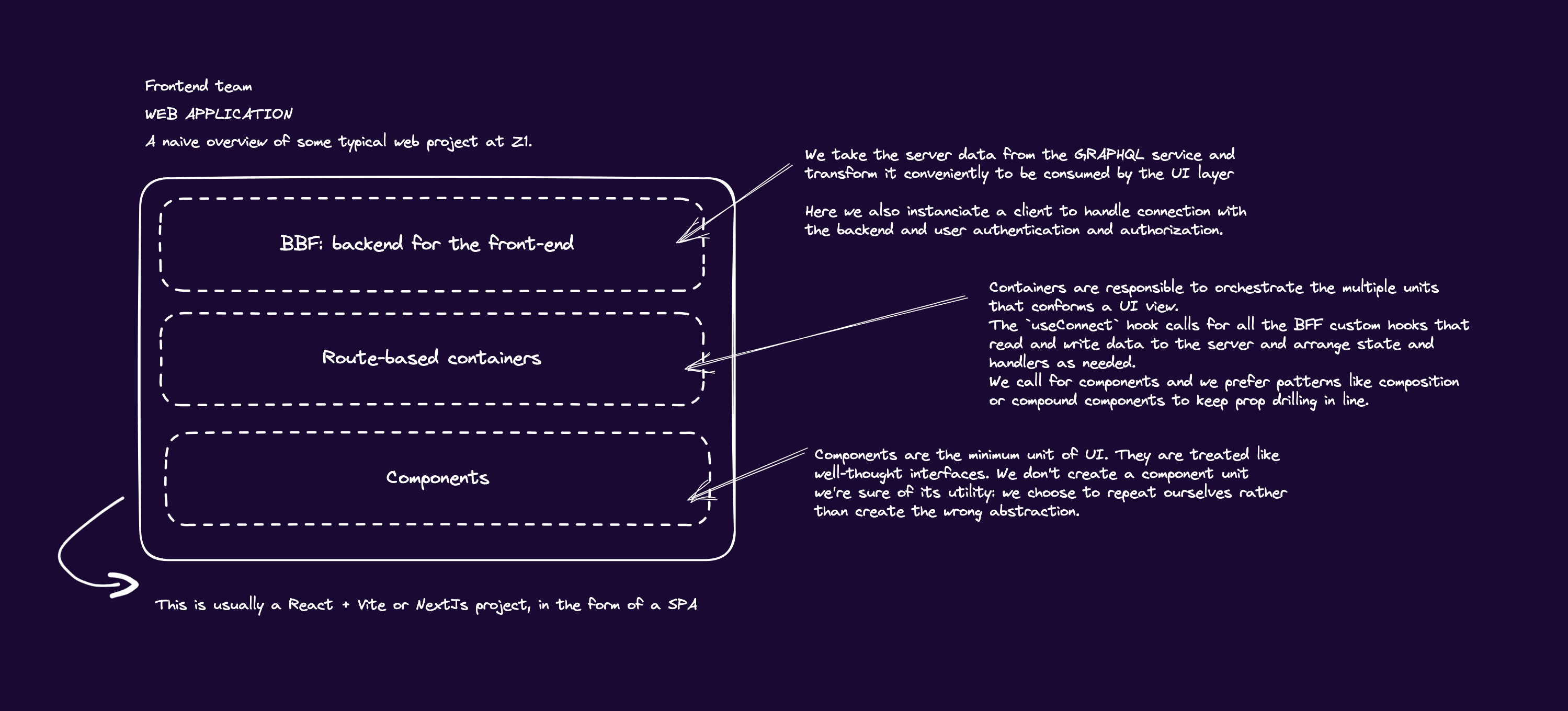
Our main pattern for structuring code is to use route-based view containers. Container components are an architectural pattern for the separation of concerns. It dictates a separation between the view and the application logic.
The container component orchestrates smaller components to form a view or part thereof. They provide a coordinated state to these components through props. This pattern has existed for a long time in React. When hooks came out, they took over because they let you connect data directly inside a component, eliminating the need for an intermediary layer like the container.
At Z1, we still bet on using containers to create a clean, scalable, and testable application. We use them to fetch all the server data from different queries, transform it, and pass it over.
To keep prop drilling in line, we use patterns like composition or compound components. This approach keeps components decoupled from server data, something hooks cannot provide. Coupling components and server data compromises the component reuse. What if we need to hook a component with a different server data? What if we want to test that component? We would need to mock those hooks and API calls.
Having components unaware of all this complexity facilitates easy reuse, refactoring, and testing. This strategy also mitigates waterfall issues in server calls, a common problem where component loading depends on other components, causing delays in rendering.
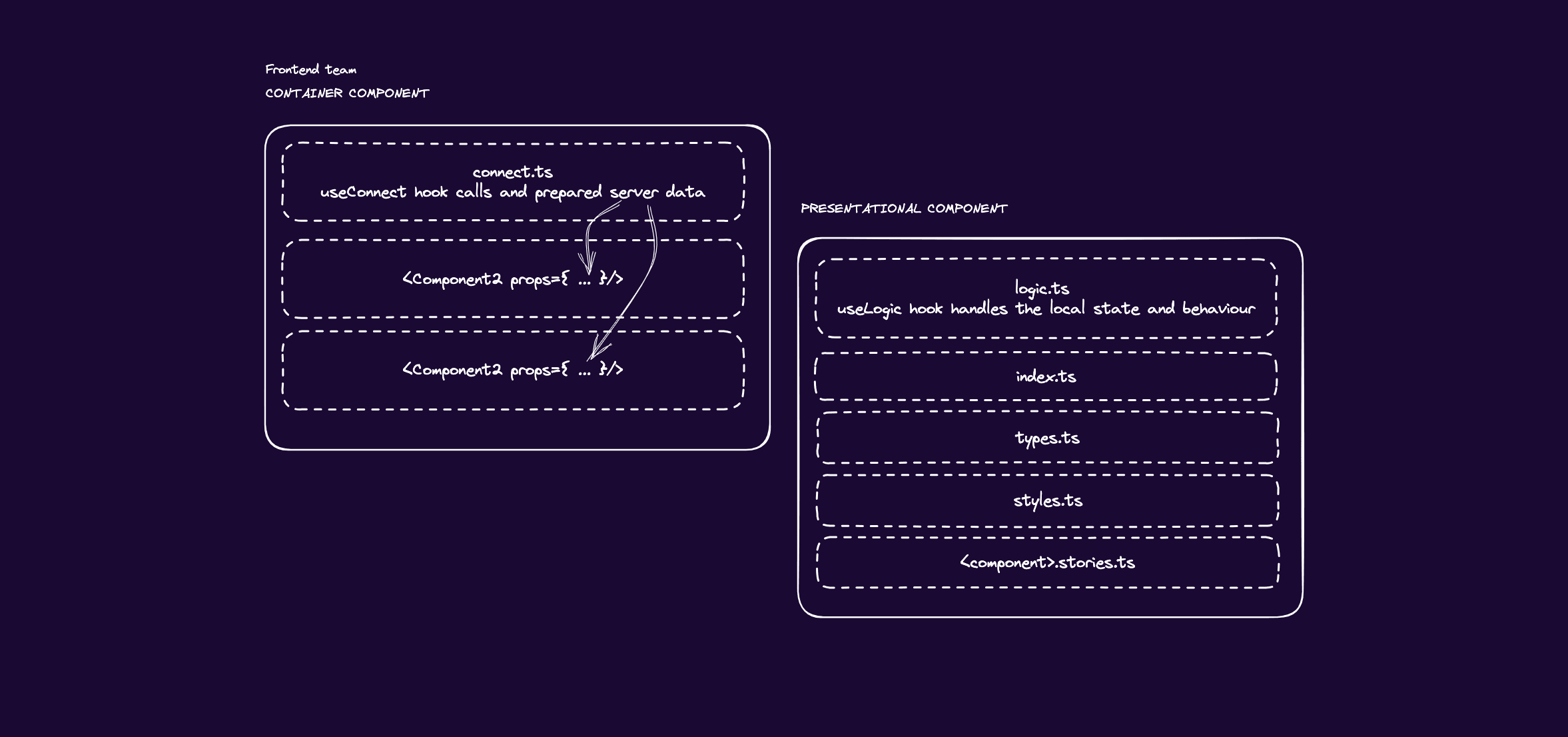
At the scope of the component, we have some conventions about file structure oriented to enforce some separation of concerns. Each component is a folder containing the following:
- A main file, index.tsx. This file imports all the component parts and exports the component declaration with its markup. We usually prefer named components, as they enforce naming consistency.
- A typing file, types.ts, contains types related to the component, such as props typing and functions interfaces.
- In a logic.tsx file, we include custom hooks that describe the logic related to the UI, forms, navigation, etc., specific to that component. For instance, if the component is an accordion, logic will be related to its visibility and interaction with its parts.
- A stories file. The name would have the pattern <componentName>.stories.txt. This file contains the Storybook stories that document and test the component behavior.
- A connect.tsx file reserved for containers. Here, we manage the server state. We would have a useConnect hook where we normalize and transform server data. Also, declare functions (handlers) for user interaction and for writing data back to the server.
- A styles.ts file. In many projects, we kept a styles file for Styled Components declaration. The team is very acquainted with this styling approach. We are moving on to Tailwind for styles as CSS-in-JS solutions are now compromised in React Server Components.
- Additional files we can find inside the component folder are:
- Unit test and component test files
- Files for declaring constants that are local to that component
- Files containing mocking data used in tests, stories and early development phases.
Lastly, we want to highlight co-location as a strategy for organizing code. Co-location means placing a component close to where it's relevant. In other words, what changes together stays together. We keep all related components, functions, and logic in a single module or folder.
We use co-location as a strategy for organizing code to achieve a more cohesive architecture.
Components specific to a view are inside that view's folder. If we need to reuse a component in a different view (and decide it is the time to abstract rather than duplicate), we would move it to a shared components folder higher in the file hierarchy. This approach results in a more cohesive architecture. It reduces cognitive load because making changes is easier when we don't have to navigate far across the application to add a new feature.
About components, interfaces, and abstractions
Our frontend team values the concept of atomic components. This approach involves structuring applications into components as decoupled units of UI, well-thought abstractions that allow for composability.
We emphasize caution against premature abstractions, though. Our rule is to await the apparent emergence of necessity. We favor the "rule of three" against the "DRY" (don't repeat yourself) rule. After repeating a functionality pattern three times, we may extract it as a component, carefully considering the best design. We often keep the functionality in the same file to minimize cognitive load. We aim to write as little code as possible in the simplest way possible until we know enough to make abstractions.
A component (any function, for that matter) has two well-defined parts. One is the interface, the part the developer interacts with when using or invoking that code. The other is the implementation, which makes the function behave as expected and fulfills the interface promise. When we create a function, we need to ponder about the most suitable interface we can offer the rest of the developers (and our future selves) to use.
As developers, we are writers, and as such, we need to write for our readers.
Types also help us think about the inputs and outputs of the function's interface. As developers, we are writers, and as such, we need to write for our readers. The interface must hide all complexity. The goal is to understand the code without knowing anything about the implementation. When refactoring some functions, we would keep changes at the implementation level, preserving the interface. All this eventually adds up to a better developer experience.
One tool we love and use in almost every project is Storybook. It doubles down as a design for documenting components and designing them. Its story format encourages us to think about components from an interface perspective, specifying necessary inputs and expected output. Storybook aids us in developing and testing components in isolation, promoting a form of Component-Driven Development.
A backend for the frontend
As mentioned earlier, our backend teams provide us with a GraphQL API service to interact with the server data. Our frontend application code reserves space to manage all things related to GraphQL. This directory has the role of a backend for the fronted (BFF) to us.
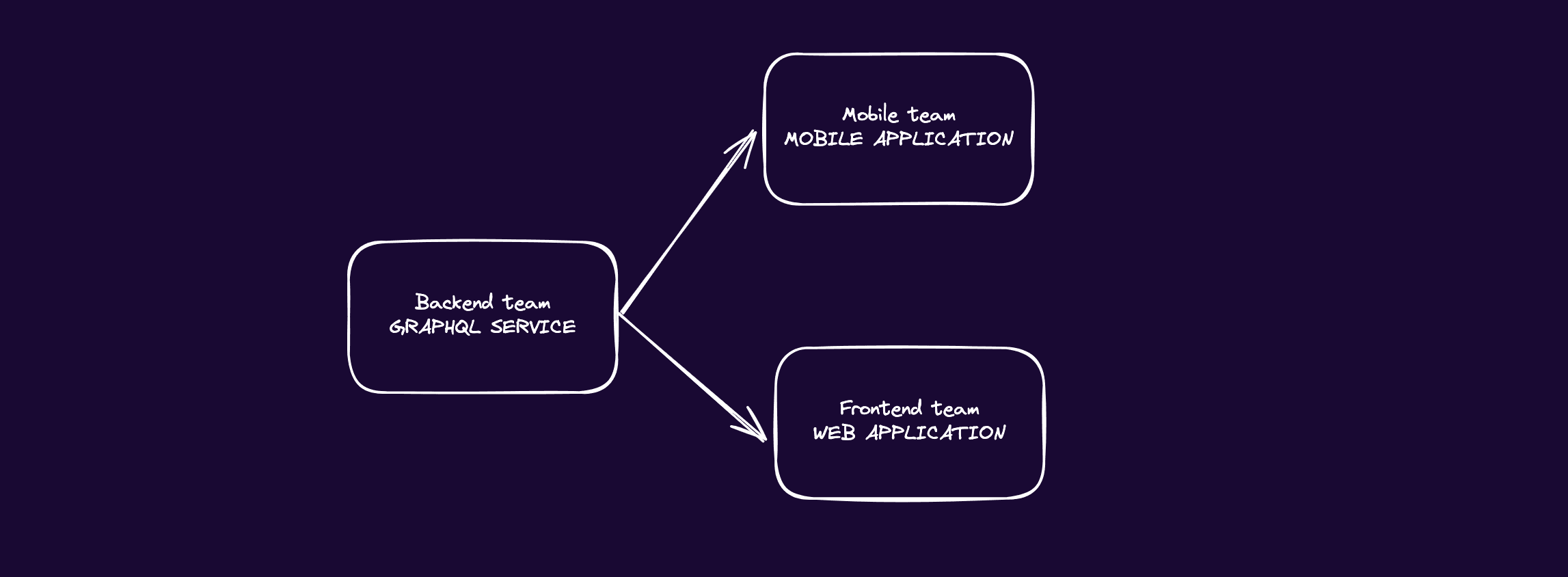
That GraphQL service is independent of the frontend layer. This is a deliberate and strategic design decision to make the API resilient to changes. We might have, now or in the future, another client dependent on this API, such as a mobile application. But, most importantly, the frontend layer will undoubtedly evolve. We need the data service to be able to accommodate that evolution. If we couple both layers, parts of the services would become obsolete, making changes harder.
For that reason, a BBF in the frontend is needed. We would set up data for our view layer in this intermediary layer. We would have a client to establish communication with the GraphQL service and handle authorization and authentication. We would create custom hooks to query, mutate, and export data or functions that our containers would consume.
We typically have two hooks for a given feature: one for querying, transforming, and exporting data. Another is for mutating data and exporting functions with the necessary denormalization and error handling. This pattern aligns with the CQRS principle, which encourages a distinction between the operations that retrieve data and the ones that change it.
Frontend and backend tight collaboration is vital when working on projects for MVPs and startups, where things would evolve quickly.
Besides, in the development phase, we work with our backend teammates. We found out that this parallel collaboration is more efficient. It reduces changes in context and encourages teamwork and good communication. Tight collaboration is vital when working on projects for MVPs and startups, where things would evolve quickly.
As you can imagine, data models would surely change in these dynamic scenarios. Type fields would be added, removed, or renamed. Having a BFF layer is valuable to centralize these modifications' impact. By doing this, we avoid the headache of having updates ripple through the entire application. No more risky and time-consuming refactors—just smooth sailing through the development waves.
Quality automation
At Z1, we're all about automating for efficiency, especially when it comes to maintaining code quality and standards. Our go-to tools for this mission are:
- ESLint, Prettier, and StyleLint in the frontend, set up from the get-go in every project.
- Ruff on the backend. The team also follows the PEP8 style guide.
Writing software is a team activity. The great thing about ESLint is that it does not dictate how our code should look but empowers our team to define what clean and readable code means for us, automating compliance as we code.
If we find ourselves repeatedly correcting or commenting on a recurring error with the team, there is probably a lint rule we can add to automate the solution. We used it to automate our syntax, naming, and style preferences, detect obsolete code usage, prevent logical or syntax errors, enforce the use or avoidance of specific patterns, etc.
The best conventions are the ones that are automated. We save lots of time remembering these preferences and manually reviewing code to gain a more consistent and healthy codebase. We integrate these tools in our IDE and check code when we commit it to the source, thanks to using Git hooks.
Code delivery
Finally, we check that everything integrates appropriately by using these tools with GitHub Actions. Upon merging each pull request, GitHub Actions runs all code quality checks, including unit testing. If everything has gone swiftly, a deployment to the corresponding environment takes place.
We usually operate in three distinct environments:
- Development, where we implement and refine new features.
- Staging, a space for rigorous testing and client demonstrations.
- Production, where our solutions come to life.
Afterword
In John Ousternout's Philosophy of Software Design, he explores the distinction between strategic and tactical programming.
- Tactical programming allows for swift feature development, sometimes at the expense of unnecessary complexity.
- On the other hand, strategic programming is geared for the long run, focusing on refactoring and continuous improvements in the app's design.
The saying "Code is a liability" is a common refrain in programming, highlighting the costly nature of written code in terms of maintainability. Keeping things simple and lean is always a plus, recognizing that complexity builds incrementally.
At Z1, we embrace a Boy Scout mindset, always striving to leave the codebase better than we found it.
Once a codebase reaches a certain level of complexity, it becomes challenging to fix, manage, and introduce new features. Even in the context of MVPs or startup products, striking the right balance between strategic and tactical programming is crucial for success. At Z1, we embrace a Boy Scout mindset, always striving to leave the codebase better than we found it.

